investigacion 4
BIOS
| BIOS: Basic Input/Output System | |
 | |
|
El Sistema Básico de Entrada/Salida o BIOS (Basic Input-Output System ) es un código de software que localiza y reconoce todos los dispositivos necesarios para cargar el sistema operativo en la RAM; es un software muy básico instalado en la placa base que permite que esta cumpla su cometido. Proporciona la comunicación de bajo nivel, el funcionamiento y configuración del hardware del sistema que, como mínimo, maneja el teclado y proporciona salida básica (emitiendo pitidos normalizados por el altavoz de la computadora si se producen fallos) durante el arranque. El BIOS usualmente está escrito en lenguaje ensamblador. El primer término BIOS apareció en el sistema operativo CP/M, y describe la parte de CP/M que se ejecutaba durante el arranque y que iba unida directamente al hardware (las máquinas de CP/M usualmente tenían un simple cargador arrancable en la ROM, y nada más). La mayoría de las versiones de MS-DOS tienen un archivo llamado "IBMBIO.COM" o "IO.SYS" que es análogo al CP/M BIOS.
El BIOS (Basic Input-Output System) es un sistema básico de entrada/salida que normalmente pasa inadvertido para el usuario final de computadoras. Se encarga de encontrar el sistema operativo y cargarlo en memoria RAM. Posee un componente de hardware y otro de software, este último brinda una interfaz generalmente de texto que permite configurar varias opciones del hardware instalado en el PC, como por ejemplo el reloj, o desde qué dispositivos de almacenamiento iniciará el sistema operativo (Windows, GNU/Linux, Mac OS X, etc.).
El BIOS gestiona al menos el teclado de la computadora, proporcionando incluso una salida bastante básica en forma de sonidos por el altavoz incorporado en la placa base cuando hay algún error, como por ejemplo un dispositivo que falla o debería ser conectado. Estos mensajes de error son utilizados por los técnicos para encontrar soluciones al momento de armar o reparar un equipo. Basic Input/Output System - Sistema básico de entrada/salida de datos). Programa que reside en la memoria EPROM (Ver Memoria BIOS no-volátil). Es un programa tipo firmware. La BIOS es una parte esencial del hardware que es totalmente configurable y es donde se controlan los procesos del flujo de información en el bus del ordenador, entre el sistema operativo y los demás periféricos. También incluye la configuración de aspectos importantísimos de la máquina.
El mercado de los BIOSLa gran mayoría de los proveedores de placas madre de computadoras personales delega a terceros la producción del BIOS y un conjunto de herramientas. Estos se conocen como "proveedores independientes de BIOS" o IBV (del inglés independent BIOS vendor). Los fabricantes de placas madre después personalizan este BIOS según su propio hardware. Por esta razón, la actualización del BIOS normalmente se obtiene directamente del fabricante de placas madre. El fabricante puede publicar actualizaciones del firmware por medio de su pagina web, pero una mala compatibilidad con el Hardware puede provocar que el sistema no vuelva a arrancar inutilizándolo hasta reescribir el BIOS directamente en el circuito integrado donde se almacena con un programador de memorias. Los principales proveedores de BIOS son American Megatrends (AMI), General Software, Insyde Software, y Phoenix Technologies (que compró Award Software International en 1998
RAM son las siglas de random access memory, un tipo de memoria de ordenador a la que se puede acceder aleatoriamente; es decir, se puede acceder a cualquier byte de memoria sin acceder a los bytes precedentes. La memoria RAM es el tipo de memoria más común en ordenadores y otros dispositivos como impresorasRAM) es la memoria desde donde el procesador recibe las instrucciones y guarda los resultados La frase memoria RAM se utiliza frecuentemente para referirse a los módulos de memoria que se usan en los computadores personales y servidores. En el sentido estricto, los modulos de memoria contienen un tipo, entre varios de memoria de acceso aleatorio, ya que las ROM, memorias Flash, caché (SRAM), los registros en procesadores y otras unidades de procesamiento también poseen la cualidad de presentar retardos de acceso iguales para cualquier posición. Los módulos de RAM son la presentación comercial de este tipo de memoria, que se compone de circuitos integrados soldados sobre un circuito impreso, en otros dispositivos como las consolas de videojuegos, esa misma memoria va soldada sobre la placa principal.
La frase memoria RAM se utiliza frecuentemente para referirse a los módulos de memoria que se usan en los computadores personales y servidores. En el sentido estricto, los modulos de memoria contienen un tipo, entre varios de memoria de acceso aleatorio, ya que las ROM, memorias Flash, caché (SRAM), los registros en procesadores y otras unidades de procesamiento también poseen la cualidad de presentar retardos de acceso iguales para cualquier posición. Los módulos de RAM son la presentación comercial de este tipo de memoria, que se compone de circuitos integrados soldados sobre un circuito impreso, en otros dispositivos como las consolas de videojuegos, esa misma memoria va soldada sobre la placa principal.
Es en esta parte del tiempo, en donde se puede hablar de un área de trabajo para la mayor parte del software de un computador. La RAM continua siendo volátil por lo que posee la capacidad de perder la información una vez que se agote su fuente de energía.[1] Existe una memoria intermedia entre el procesador y la RAM, llamada caché, pero ésta sólo es una copia (de acceso rápido) de la memoria principal (típicamente discos duros) almacenada en los módulos de RAM.[1]


La denominación “de Acceso aleatorio” surgió para diferenciarlas de las memoria de acceso secuencial, debido a que en los comienzos de la computación, las memorias principales (o primarias) de las computadoras eran siempre de tipo RAM y las memorias secundarias (o masivas) eran de acceso secuencial (cintas o tarjetas perforadas). Es frecuente pues que se hable de memoria RAM para hacer referencia a la memoria principal de una computadora, pero actualmente la denominación no es precisa.
Uno de los primeros tipos de memoria RAM fue la memoria de núcleo magnético, desarrollada entre 1949 y 1952 y usada en muchos computadores hasta el desarrollo de circuitos integrados a finales de los años 60 y principios de los 70. Antes que eso, las computadoras usaban relés y líneas de retardo de varios tipos construidas con tubos de vacío para implementar las funciones de memoria principal con o sin acceso aleatorio.
En 1969 fueron lanzadas una de las primeras memorias RAM basadas en semiconductores de silicio por parte de Intel con el integrado 3101 de 64 bits de memoria y para el siguiente año se presentó una memoria DRAM de 1 Kibibyte, referencia 1103 que se constituyó en un hito, ya que fue la primera en ser comercializada con éxito, lo que significó el principio del fin para las memorias de núcleo magnético. En comparación con los integrados de memoria DRAM actuales, la 1103 es primitiva en varios aspectos, pero tenía un desempeño mayor que la memoria de núcleos.
En 1973 se presentó una innovación que permitió otra miniaturización y se convirtió en estándar para las memorias DRAM: la multiplexación en tiempo de la direcciones de memoria. MOSTEK lanzó la referencia MK4096 de 4Kb en un empaque de 16 pines,[2] mientras sus competidores las fabricaban en el empaque DIP de 22 pines. El esquema de direccionamiento[3] se convirtió en un estándar de facto debido a la gran popularidad que logró esta referencia de DRAM. Para finales de los 70 los integrados eran usados en la mayoría de computadores nuevos, se soldaban directamente a las placas base o se instalaban en zócalos, de manera que ocupaban un área extensa de circuito impreso. Con el tiempo se hizo obvio que la instalación de RAM sobre el impreso principal, impedía la miniaturización , entonces se idearon los primeros módulos de memoria como el SIPP, aprovechando las ventajas de la construcción modular. El formato SIMM fue una mejora al anterior, eliminando los pines metálicos y dejando unas áreas de cobre en uno de los bordes del impreso, muy similares a los de las tarjetas de expansión, de hecho los módulos SIPP y los primeros SIMM tienen la misma distribución de pines.
A finales de los 80 el aumento en la velocidad de los procesadores y el aumento en el ancho de banda requerido, dejaron rezagadas a las memorias DRAM con el esquema original MOSTEK, de manera que se realizaron una serie de mejoras en el direccionamiento como las siguientes:

- FPM-RAM (Fast Page Mode RAM)
Inspirado en técnicas como el "Burst Mode" usado en procesadores como el Intel 486,[4] se implantó un modo direccionamiento en el que el controlador de memoria envía una sola dirección y recibe a cambio esa y varias consecutivas sin necesidad de generar todas las direcciones. Esto supone un ahorro de tiempos ya que ciertas operaciones son repetitivas cuando se desea acceder a muchas posiciones consecutivas. Funciona como si deseáramos visitar todas las casas en una calle: después de la primera vez no seria necesario decir el número de la calle únicamente seguir la misma. Se fabricaban con tiempos de acceso de 70 ó 60 ns y fueron muy populares en sistemas basados en el 486 y los primeros Pentium.
- EDO-RAM (Extended Data Output RAM)
Lanzada en 1995 y con tiempos de accesos de 40 o 30 ns suponía una mejora sobre su antecesora la FPM. La EDO, también es capaz de enviar direcciones contiguas pero direcciona la columna que va utilizar mientras que se lee la información de la columna anterior, dando como resultado una eliminación de estados de espera, manteniendo activo el buffer de salida hasta que comienza el próximo ciclo de lectura.
- BEDO-RAM (Burst Extended Data Output RAM)
Fue la evolución de la EDO RAM y competidora de la SDRAM, fue presentada en 1997. Era un tipo de memoria que usaba generadores internos de direcciones y accedía a mas de una posición de memoria en cada ciclo de reloj, de manera que lograba un desempeño un 50% mejor que la EDO. Nunca salió al mercado, dado que Intel y otros fabricantes se decidieron por esquemas de memoria sincrónicos que si bien tenían mucho del direccionamiento MOSTEK, agregan funcionalidades distintas como señales de reloj.Arquitectura base
En origen, la memoria RAM se componía de hilos de cobre que atravesaban toroides de ferrita, la corriente polariza la ferrita. Mientras esta queda polarizada, el sistema puede invocar al procesador accesos a partes del proceso que antes (en un estado de reposo) no es posible acceder. En sus orígenes, la invocación a la RAM, producía la activación de contactores, ejecutando instrucciones del tipo AND, OR y NOT. La programación de estos elementos, consistía en la predisposición de los contactores para que, en una línea de tiempo, adquiriesen las posiciones adecuadas para crear un flujo con un resultado concreto. La ejecución de un programa, provocaba un ruido estruendoso en la sala en la cual se ejecutaba dicho programa, por ello el área central de proceso estaba separada del área de control por mamparas insonorizadas.
Con las nuevas tecnologías, las posiciones de la ferrita se ha ido sustituyendo por, válvulas de vacío, transistores y en las últimas generaciones, por un material sólido dieléctrico. Dicho estado estado sólido dieléctrico tipo DRAM permite que se pueda tanto leer como escribir información.
Uso por el sistema
Se utiliza como memoria de trabajo para el sistema operativo, los programas y la mayoría del software. Es allí donde se cargan todas las instrucciones que ejecutan el procesador y otras unidades de cómputo. Se denominan "de acceso aleatorio" porque se puede leer o escribir en una posición de memoria con un tiempo de espera igual para cualquier posición, no siendo necesario seguir un orden para acceder a la información de la manera más rápida posible.
Módulos de memoria RAM

Los módulos de memoria RAM son tarjetas de circuito impreso que tienen soldados integrados de memoria DRAM por una o ambas caras. La implementación DRAM se basa en una topología de Circuito eléctrico que permite alcanzar densidades altas de memoria por cantidad de transistores, logrando integrados de decenas o cientos de Megabits. Además de DRAM, los módulos poseen un integrado que permiten la identificación del mismos ante el computador por medio del protocolo de comunicación SPD.
La conexión con los demás componentes se realiza por medio de un área de pines en uno de los filos del circuito impreso, que permiten que el modulo al ser instalado en un zócalo apropiado de la placa base, tenga buen contacto eléctrico con los controladores de memoria y las fuentes de alimentación. Los primeros módulos comerciales de memoria eran SIPP de formato propietario, es decir no había un estándar entre distintas marcas. Otros módulos propietarios bastante conocidos fueron los RIMM, ideados por la empresa RAMBUS.
La necesidad de hacer intercambiable los módulos y de utilizar integrados de distintos fabricantes condujo al establecimiento de estándares de la industria como los JEDEC.
- Módulos SIMM: Formato usado en computadores antiguos. Tenían un bus de datos de 16 o 32 bits
- Módulos DIMM: Usado en computadores de escritorio. Se caracterizan por tener un bus de datos de 64 bits.
- Módulos SO-DIMM: Usado en computadores portátiles. Formato miniaturizado de DIMM.
Relación con el resto del sistema

Dentro de la jerarquía de memoria la RAM se encuentra en un nivel después de los registros del procesador y de las cachés. Es una memoria relativamente rápida y de una capacidad media: sobre el año 2010), era fácil encontrar memorias con velocidades de más de 1 Ghz, y capacidades de hasta 8 GB por módulo, llegando a verse memorias pasando la barrera de los 3 Ghz por esa misma fecha mediante overclock. La memoria RAM contenida en los módulos, se conecta a un controlador de memoria que se encarga de gestionar las señales entrantes y salientes de los integrados DRAM. Algunas señales son las mismas que se utilizan para utilizar cualquier memoria: Direcciones de las posiciones, datos almacenados y señales de control.
El controlador de memoria debe ser diseñado basándose en una tecnología de memoria, por lo general soporta solo una, pero existen excepciones de sistemas cuyos controladores soportan dos tecnologías (por ejemplo SDR y DDR o DDR1 y DDR2), esto sucede en las épocas transitorias de una nueva tecnología de RAM. Los controladores de memoria en sistemas como PC y servidores se encuentran embebidos en el llamado "North Bridge" o "Puente Norte" de la placa base; o en su defecto, dentro del mismo procesador (en el caso de los procesadores desde AMD Athlon 64 e Intel Core i7) y son los encargados de manejar la mayoría de información que entra y sale del procesador.
Las señales básicas en el módulo están divididas en dos buses y un conjunto misceláneo de líneas de control y alimentación. Entre todas forman el bus de memoria:
- Bus de datos: Son las líneas que llevan información entre los integrados y el controlador. Por lo general están agrupados en octetos siendo de 8,16,32 y 64 bits, cantidad que debe igualar el ancho del bus de datos del procesador. En el pasado, algunos formatos de modulo, no tenían un ancho de bus igual al del procesador.En ese caso había que montar módulos en pares o en situaciones extremas, de a 4 módulos, para completar lo que se denominaba banco de memoria, de otro modo el sistema no funciona. Esa es la principal razón de haber aumentar el número de pines en los módulos, igualando el ancho de bus de procesadores como el Pentium de 64 bits a principios de los 90.
- Bus de direcciones: Es un bus en el cual se colocan las direcciones de memoria a las que se requiere acceder. No es igual al bus de direcciones del resto del sistema, ya que está multiplexado de manera que la dirección se envía en dos etapas.Para ello el controlador realiza temporizaciones y usa las líneas de control. En cada estándar de módulo se establece un tamaño máximo en bits de este bus, estableciendo un límite teórico de la capacidad máxima por módulo.
- Señales misceláneas: Entre las que están las de la alimentación (Vdd, Vss) que se encargan de entregar potencia a los integrados. Están las líneas de comunicación para el integrado de presencia que da información clave acerca del módulo. También están las líneas de control entre las que se encuentran las llamadas RAS (row address strobe) y CAS (column address strobe) que controlan el bus de direcciones y las señales de reloj en las memorias sincrónicas SDRAM.
Entre las características sobresalientes del controlador de memoria, está la capacidad de manejar la tecnología de canal doble (Dual Channel), tres canales, o incluso cuatro para los procesadores venideros; donde el controlador maneja bancos de memoria de 128 bits. Aunque el ancho del bus de datos del procesador sigue siendo de 64 bits, el controlador de memoria puede entregar los datos de manera intercalada, optando por uno u otro canal, reduciendo las latencias vistas por el procesador. La mejora en el desempeño es variable y depende de la configuración y uso del equipo. Esta característica ha promovido la modificación de los controladores de memoria, resultando en la aparición de nuevos chipsets (la serie 865 y 875 de Intel) o de nuevos zócalos de procesador en los AMD (el 939 con canal doble , reemplazo el 754 de canal sencillo). Los equipos de gama media y alta por lo general se fabrican basados en chipsets o zócalos que soportan doble canal o superior.
Tecnologías de memoria
La tecnología de memoria actual usa una señal de sincronización para realizar las funciones de lectura-escritura de manera que siempre esta sincronizada con un reloj del bus de memoria, a diferencia de las antiguas memorias FPM y EDO que eran asíncronas. Hace más de una década toda la industria se decantó por las tecnologías síncronas, ya que permiten construir integrados que funcionen a una frecuencia superior a 66 Mhz (A día de hoy, se han superado con creces los 1600 Mhz).

SDR SDRAM
Memoria síncrona, con tiempos de acceso de entre 25 y 10 ns y que se presentan en módulos DIMM de 168 contactos. Fue utilizada en los Pentium II y en los Pentium III , así como en los AMD K6, AMD Athlon K7 y Duron. Está muy extendida la creencia de que se llama SDRAM a secas, y que la denominación SDR SDRAM es para diferenciarla de la memoria DDR, pero no es así, simplemente se extendió muy rápido la denominación incorrecta. El nombre correcto es SDR SDRAM ya que ambas (tanto la SDR como la DDR) son memorias síncronas dinámicas. Los tipos disponibles son:
- PC100: SDR SDRAM, funciona a un máx de 100 MHz.
- PC133: SDR SDRAM, funciona a un máx de 133 MHz.
DDR SDRAM
Memoria síncrona, envía los datos dos veces por cada ciclo de reloj. De este modo trabaja al doble de velocidad del bus del sistema, sin necesidad de aumentar la frecuencia de reloj. Se presenta en módulos DIMM de 184 contactos. Los tipos disponibles son:
- PC2100 o DDR 266: funciona a un máx de 133 MHz.
- PC2700 o DDR 333: funciona a un máx de 166 MHz.
- PC3200 o DDR 400: funciona a un máx de 200 MHz.
DDR2 SDRAM

Las memorias DDR 2 son una mejora de las memorias DDR (Double Data Rate), que permiten que los búferes de entrada/salida trabajen al doble de la frecuencia del núcleo, permitiendo que durante cada ciclo de reloj se realicen cuatro transferencias. Se presentan en módulos DIMM de 240 contactos. Los tipos disponibles son:
- PC2-4200 o DDR2-533: funciona a un máx de 533 MHz.
- PC2-5300 o DDR2-667: funciona a un máx de 667 MHz.
- PC2-6400 o DDR2-800: funciona a un máx de 800 MHz.
- PC2-8600 o DDR2-1066: funciona a un máx de 1066 MHz.
DDR3 SDRAM
Las memorias DDR 3 son una mejora de las memorias DDR 2, proporcionan significantes mejoras en el rendimiento en niveles de bajo voltaje, lo que lleva consigo una disminución del gasto global de consumo. Los módulos DIMM DDR 3 tienen 240 pines, el mismo número que DDR 2; sin embargo, los DIMMs son físicamente incompatibles, debido a una ubicación diferente de la muesca. Los tipos disponibles son:
- PC3-8600 o DDR3-1066: funciona a un máx de 1066 MHz.
- PC3-10600 o DDR3-1333: funciona a un máx de 1333 MHz.
- PC3-12800 o DDR3-1600: funciona a un máx de 1600 MHz.
RDRAM (Rambus DRAM)
Memoria de gama alta basada en un protocolo propietario creado por la empresa Rambus, lo cual obliga a sus compradores a pagar regalías en concepto de uso. Esto ha hecho que el mercado se decante por la tecnología DDR, libre de patentes, excepto algunos servidores de grandes prestaciones (Cray) y la consola PlayStation 3. La RDRAM se presenta en módulos RIMM de 184 contactos.
Detección y corrección de errores
Existen dos clases de errores en los sistemas de memoria, las fallas (Hard fails) que son daños en el hardware y los errores (soft errors) provocados por causas fortuitas. Los primeros son relativamente fáciles de detectar (en algunas condiciones el diagnóstico es equivocado), los segundos al ser resultado de eventos aleatorios, son más difíciles de hallar. En la actualidad la confiabilidad de las memorias RAM frente a los errores, es suficientemente alta como para no realizar verificación sobre los datos almacenados, por lo menos para aplicaciones de oficina y caseras. En los usos más críticos, se aplican técnicas de corrección y detección de errores basadas en diferentes estrategias:
- La técnica del bit de paridad consiste en guardar un bit adicional por cada byte de datos, y en la lectura se comprueba si el número de unos es par (paridad par) o impar (paridad impar), detectándose así el error.
- Una técnica mejor es la que usa ECC, que permite detectar errores de 1 a 4 bits y corregir errores que afecten a un sólo bit esta técnica se usa sólo en sistemas que requieren alta fiabilidad.
Por lo general los sistemas con cualquier tipo de protección contra errores tiene un costo más alto, y sufren de pequeñas penalizaciones en desempeño, con respecto a los sistemas sin protección. Para tener un sistema con ECC o paridad, el chipset y las memorias debe tener soportar esas tecnologías. La mayoría de placas base no poseen dicho soporte.
Para los fallos de memoria se pueden utilizar herramientas de software especializadas que realizan pruebas integrales sobre los módulos de memoria RAM. Entre estos programas uno de los más conocidos es la aplicación Memtest86+ que detecta fallos de memoria.
Memoria RAM registrada
Es un tipo de módulo usado frecuentemente en servidores y equipos especiales. Poseen circuitos integrados que se encargan de repetir las señales de control y direcciones. Las señales de reloj son reconstruidas con ayuda del PLL que está ubicado en el módulo mismo. Las señales de datos pasan directamente del bus de memoria a los CI de memoria DRAM.
Estas características permiten conectar múltiples módulos de memoria (más de 4) de alta capacidad sin que haya perturbaciones en las señales del controlador de memoria, haciendo posible sistemas con gran cantidad de memoria principal (8 a 16 GiB). Con memorias no registradas, no es posible, debido a los problemas surgen de sobrecarga eléctrica a las señales enviadas por el controlador, fenómeno que no sucede con las registradas por estar de algún modo aisladas.
Entre las desventajas de estos módulos están el hecho de que se agrega un ciclo de retardo para cada solicitud de acceso a una posición no consecutiva y por supuesto el precio, que suele ser mucho más alto que el de las memorias de PC. Este tipo de módulos es incompatible con los controladores de memoria que no soportan el modo registrado, a pesar de que se pueden instalar físicamente en el zócalo. Se pueden reconocer visualmente porque tienen un integrado mediano, cerca del centro geométrico del circuito impreso, además de que estos módulos suelen ser algo más altos.
RON
Un CD-ROM (siglas del inglés Compact Disc - Read Only Memory, "Disco Compacto - Memoria de Sólo Lectura"), es un disco compacto utilizado para almacenar información no volátil, el mismo medio utilizado por los CD de audio, puede ser leído por un computador con lectora de CD. Un CD-ROM es un disco de plástico plano con información digital codificada en una espiral desde el centro hasta el borde exterior.
El denominado Yellow Book (o Libro Amarillo) que define el CD-ROM estándar fue establecido en 1985 por Sony y Philips. Pertenece a un conjunto de libros de colores conocido como Rainbow Books que contiene las especificaciones técnicas para todos los formatos de discos compactos.
Microsoft y Apple Computer fueron entusiastas promotores del CD-ROM. John Sculley, que era CEO de Apple, dijo en 1987 que el CD-ROM revolucionaría el uso de computadoras personales.
La Unidad de CD-ROM debe considerarse obligatoria en cualquier computador que se ensamble o se construya actualmente, porque la mayoría del software se distribuye en CD-ROM. Algunas de estas unidades leen CD-ROM y graban sobre los discos compactos de una sola grabada(CD-RW). Estas unidades se llaman quemadores, ya que funcionan con un láser que "quema" la superficie del disco para grabar la información.
Actualmente, aunque aún se utilizan, están empezando a caer en desuso desde que empezaron a ser sustituidos por unidades de DVD. Esto se debe principalmente a las mayores posibilidades de información, ya que un DVD-ROM supera en capacidad a un CD-ROM
La memoria ROM, (read-only memory) o memoria de sólo lectura, es la memoria que se utiliza para almacenar los programas que ponen en marcha el ordenador y realizan los diagnósticos. La memoria ROM es aquella memoria de almacenamiento que permite sólo la lectura de la información y no su destrucción, independientemente de la presencia o no de una fuente de energía que la alimente.
La memoria de sólo lectura o ROM (acrónimo en inglés de read-only memory) es una clase de medio de almacenamiento utilizado en ordenadores y otros dispositivos electrónicos. Los datos almacenados en la ROM no se pueden modificar -al menos no de manera rápida o fácil- y se utiliza principalmente para contener el firmware (programa que está estrechamente ligado a hardware específico, y es poco probable que requiera actualizaciones frecuentes) u otro contenido vital para el funcionamiento del dispositivo.
En su sentido más estricto, se refiere sólo a máscara ROM -en inglés MROM- (el más antiguo tipo de estado sólido ROM), que se fabrica con los datos almacenados de forma permanente, y por lo tanto, su contenido no puede ser modificado. Sin embargo, las ROM más modernas, como EPROM y Flash EEPROM se pueden borrar y volver a programar varias veces, aún siendo descritos como "memoria de sólo lectura (ROM), porque el proceso de reprogramación en general es poco frecuente, relativamente lento y, a menudo, no se permite la escritura en lugares aleatorios de la memoria. A pesar de la simplicidad de la ROM, los dispositivos reprogramables son más flexibles y económicos, por dicha razón, las máscaras ROM no se suelen encontrar en hardware producido a partir de 2007
Procesador
El término "procesador" puede referirse a los siguientes artículos:
- Microprocesador, un circuito integrado que contiene todos los elementos de la CPU.
- CPU, el elemento que interpreta las instrucciones y procesa los datos de los programas de computadora.
- Graphics Processing Unit o Unidad de Procesamiento Gráfico, es un procesador dedicado exclusivamente a procesamiento de gráficos.
- Physics processing unit o Unidad de Procesamiento Físico es un microprocesador dedicado, diseñado para manejar cálculos físicos.
- Procesador digital de señal (DSP), un sistema digital generalmente dedicado a interpretar señales analógicas a muy alta velocidad.
- Front end processor es un pequeño computador que sirve de a un computador host como interfaz para un número de redes.
- Data Processor es un sistema que procesa datos.
- Procesador de textos, un software informático destinado a la creación y edición de documentos de texto


Sistema operativ


Un Sistema operativo (SO) es un software que actúa de interfaz entre los dispositivos de hardware y los programas usados por el usuario para utilizar un computador.[1] Es responsable de gestionar, coordinar las actividades y llevar a cabo el intercambio de los recursos y actúa como estación para las aplicaciones que se ejecutan en la máquina.
Nótese que es un error común muy extendido denominar al conjunto completo de herramientas sistema operativo, pues este, es sólo el núcleo y no necesita de entorno operador para estar operativo y funcional.[2] [3] Uno de los más prominentes ejemplos de esta diferencia, es el SO Linux,[4] el cual junto a las herramientas GNU, forman las llamadas distribuciones Linux.
Este error de precisión, se debe a la modernización de la informática llevada a cabo a finales de los 80, cuando la filosofía de estructura básica de funcionamiento de los grandes computadores[5] se rediseñó a fin de llevarla a los hogares y facilitar su uso, cambiando el concepto de computador multiusuario, (muchos usuarios al mismo tiempo) por un sistema monousuario (únicamente un usuario al mismo tiempo) más sencillo de gestionar.[6] (Véase AmigaOS, beOS o MacOS como los pioneros[7] de dicha modernización, cuando los Amiga, fueron bautizados con el sobrenombre de Video Toasters[8] por su capacidad para la Edición de vídeo en entorno multitarea round robin, con gestión de miles de colores e interfaces intuitivos para diseño en 3D con programas como Imagine[9] o Scala multimedia, entre muchos otros.)[10]
Uno de los propósitos de un sistema operativo como programa estación principal, consiste en gestionar los recursos de localización y protección de acceso del hardware, hecho que alivia a los programadores de aplicaciones de tener que tratar con estos detalles. Se encuentran en la mayoría de los aparatos electrónicos que utilizan microprocesadores para funcionar. (teléfonos móviles, reproductores de DVD, computadoras, radios, etc.)
Parte de la infraestructura de la World Wide Web está compuesta por el Sistema Operativo de Internet, creado por Cisco Systems para gestionar equipos de interconexión como los conmutadores y los enrutadores.
Sistemas operativos multiprogramados
Surge un nuevo avance en el hardware: el hardware con protección de memoria. Lo que ofrece nuevas soluciones a los problemas de rendimiento:
- Se solapa el cálculo de unos trabajos con la entrada/salida de otros trabajos.
- Se pueden mantener en memoria varios programas.
- Se asigna el uso de la CPU a los diferentes programas en memoria.
Debido a los cambios anteriores, se producen cambios en el monitor residente, con lo que éste debe abordar nuevas tareas, naciendo lo que se denomina como Sistemas Operativos multiprogramados, los cuales cumplen con las siguientes funciones:
- Administrar la memoria.
- Gestionar el uso de la CPU (planificación).
- Administrar el uso de los dispositivos de E/S.
Cuando desempeña esas tareas, el monitor residente se transforma en un sistema operativo multiprogramado.
Llamadas al sistema operativo
Definición breve: llamadas que ejecutan los programas de aplicación para pedir algún servicio al SO.
Cada SO implementa un conjunto propio de llamadas al sistema. Ese conjunto de llamadas es la interfaz del SO frente a las aplicaciones. Constituyen el lenguaje que deben usar las aplicaciones para comunicarse con el SO. Por ello si cambiamos de SO, y abrimos un programa diseñado para trabajar sobre el anterior, en general el programa no funcionará, a no ser que el nuevo SO tenga la misma interfaz. Para ello:
- Las llamadas correspondientes deben tener el mismo formato.
- Cada llamada al nuevo SO tiene que dar los mismos resultados que la correspondiente del anterior.
Modos de ejecución en un CPU
Las aplicaciones no deben poder usar todas las instrucciones de la CPU. No obstante el Sistema Operativo, tiene que poder utilizar todo el juego de instrucciones del CPU. Por ello, una CPU debe tener (al menos) dos modos de operación diferentes:
- Modo usuario: el CPU podrá ejecutar sólo las instrucciones del juego restringido de las aplicaciones.
- Modo supervisor: la CPU debe poder ejecutar el juego completo de instruc


2. Tipos de Sistemas Operativos.
Actualmente los sistemas operativos se clasifican en tres clasificaciones: sistemas operativos por su estructura (visión interna), sistemas operativos por los servicios que ofrecen y sistemas operativos por la forma en que ofrecen sus servicios (visión externa).
3. Sistemas Operativos por Servicios(Visión Externa).
Esta clasificación es la más comúnmente usada y conocida desde el punto de vista del usuario final. Esta clasificación se comprende fácilmente con el cuadro sinóptico que a continuación se muestra:

Por Número de Usuarios:
Sistema Operativo Monousuario.
Los sistemas operativos monousuarios son aquéllos que soportan a un usuario a la vez, sin importar el número de procesadores que tenga la computadora o el número de procesoso tareas que el usuario pueda ejecutar en un mismo instante de tiempo. Las computadoras personales típicamente se han clasificado en este renglón.
En otras palabras los sistemas monousuarios son aquellos que nada más puede atender a un solo usuario, gracias a las limitaciones creadas por el hardware, los programas o el tipo de aplicación que se este ejecutando.
Sistema Operativo Multiusuario.
Los sistemas operativos multiusuarios son capaces de dar servicio a más de un usuario a la vez, ya sea por medio de varias terminales conectadas a la computadora o por medio de sesiones remotas en una redde comunicaciones. No importa el número de procesadores en la máquina ni el número de procesos que cada usuario puede ejecutar simultáneamente.
En esta categoría se encuentran todos los sistemas que cumplen simultáneamente las necesidades de dos o más usuarios, que comparten mismos recursos. Este tipo de sistemas se emplean especialmente en redes. En otras palabras consiste en el fraccionamiento del tiempo (timesharing).
Por el Número de Tareas:
Sistema Operativo Monotarea.
Los sistemas monotarea son aquellos que sólo permiten una tarea a la vez por usuario. Puede darse el caso de un sistema multiusuario y monotarea, en el cual se admiten varios usuarios al mismo tiempo pero cada uno de ellos puede estar haciendo solo una tarea a la vez.
Los sistemas operativos monotareas son más primitivos y, solo pueden manejar un proceso en cada momento o que solo puede ejecutar las tareas de una en una.
Sistema Operativo Multitarea.
Un sistema operativo multitarea es aquél que le permite al usuario estar realizando varias labores al mismo tiempo.
Es el modo de funcionamiento disponible en algunos sistemas operativos, mediante el cual una computadora procesa varias tareas al mismo tiempo. Existen varios tipos de multitareas. La conmutación de contextos (context Switching) es un tipo muy simple de multitarea en el que dos o más aplicaciones se cargan al mismo tiempo, pero en el que solo se esta procesando la aplicación que se encuentra en primer plano (la que ve el usuario. En la multitarea cooperativa, la que se utiliza en el sistema operativo Macintosh, las tareas en segundo plano reciben tiempo de procesado durante los tiempos muertos de la tarea que se encuentra en primer plano (por ejemplo, cuando esta aplicación esta esperando informacióndel usuario), y siempre que esta aplicación lo permita. En los sistemas multitarea de tiempo compartido, como OS/2, cada tarea recibe la atención del microprocesador durante una fracción de segundo.
Un sistema operativo multitarea puede estar editando el códigofuente de un programa durante su depuración mientras compila otro programa, a la vez que está recibiendo correo electrónico en un proceso en background. Es común encontrar en ellos interfaces gráficas orientadas al uso de menús y el ratón, lo cual permite un rápido intercambio entre las tareas para el usuario, mejorando su productividad.
Un sistema operativo multitarea se distingue por su capacidad para soportar la ejecución concurrente de dos o más procesos
activos. La multitarea se implementa generalmente manteniendo el código y los datos de varios procesos simultáneamente en memoria y multiplexando el procesador y los dispositivos de E/S entre ellos.
La multitarea suele asociarse con soporte hardware y software para protección de memoria con el fin de evitar que procesos corrompan el espacio de direcciones y el comportamiento de otros procesos residentes.
Por el Número de Procesadores:
Sistema Operativo de Uniproceso.
Un sistema operativo uniproceso es aquél que es capaz de manejar solamente un procesador de la computadora, de manera que si la computadora tuviese más de uno le sería inútil. El ejemplo más típico de este tipo de sistemas es el DOS y MacOS.
Sistema Operativo de Multiproceso.
Un sistema operativo multiproceso se refiere al número de procesadores del sistema, que es más de uno y éste es capaz de usarlos todos para distribuir su carga de trabajo. Generalmente estos sistemas trabajan de dos formas: simétrica o asimétricamente.
Asimétrica.
Cuando se trabaja de manera asimétrica, el sistema operativo selecciona a uno de los procesadores el cual jugará el papel de procesador maestro y servirá como pivote para distribuir la carga a los demás procesadores, que reciben el nombre de esclavos.
Simétrica.
Cuando se trabaja de manera simétrica, los procesos o partes de ellos (threads) son enviados indistintamente a cual quiera de los procesadores disponibles, teniendo, teóricamente, una mejor distribución y equilibrio en la carga de trabajo bajo este esquema.
Se dice que un thread es la parte activa en memoria y corriendo de un proceso, lo cual puede consistir de un área de memoria, un conjunto de registros con valoresespecíficos, la pila y otros valores de contexto.
Un aspecto importante a considerar en estos sistemas es la forma de crear aplicaciones para aprovechar los varios procesadores. Existen aplicaciones que fueron hechas para correr en sistemas monoproceso que no toman ninguna ventaja a menos que el sistema operativo o el compilador detecte secciones de código paralelizable, los cuales son ejecutados al mismo tiempo en procesadores diferentes. Por otro lado, el programador puede modificar sus algoritmos y aprovechar por sí mismo esta facilidad, pero esta última opción las más de las veces es costosa en horas hombre y muy tediosa, obligando al programador a ocupar tanto o más tiempo a la paralelización que a elaborar el algoritmo inicial
Según, se deben observar dos tipos de requisitos cuando se construye un sistema operativo, los cuales son:
Requisitos de usuario: Sistema fácil de usar y de aprender, seguro, rápido y adecuado al uso al que se le quiere destinar.
Requisitos del software: Donde se engloban aspectos como el mantenimiento, forma de operación, restricciones de uso, eficiencia, tolerancia frente a los errores y flexibilidad.
A continuación se describen las distintas estructuras que presentan los actuales sistemas operativos para satisfacer las necesidades que de ellos se quieren obtener.
Estructura Monolítica.
Es la estructura de los primeros sistemas operativos constituidos fundamentalmente por un solo programa compuesto de un conjunto de rutinas entrelazadas de tal forma que cada una puede llamar a cualquier otra. Las características fundamentales de este tipo de estructura son:
- Construcción del programa final a base de módulos compilados separadamente que se unen a través del ligador.
- Buena definición de parámetros de enlace entre las distintas rutinas existentes, que puede provocar mucho acoplamiento.
- Carecen de protecciones y privilegios al entrar a rutinas que manejan diferentes aspectos de los recursos de la computadora, como memoria, disco, etc.

Generalmente están hechos a medida, por lo que son eficientes y rápidos en su ejecución y gestión, pero por lo mismo carecen de flexibilidad para soportar diferentes ambientes de trabajo o tipos de aplicaciones.
Estructura Jerárquica.
A medida que fueron creciendo las necesidades de los usuarios y se perfeccionaron los sistemas, se hizo necesaria una mayor organización del software, del sistema operativo, donde una parte del sistema contenía subpartes y esto organizado en forma de niveles.
Se dividió el sistema operativo en pequeñas partes, de tal forma que cada una de ellas estuviera perfectamente definida y con un claro interface con el resto de elementos.
Se constituyó una estructura jerárquica o de niveles en los sistemas operativos, el primero de los cuales fue denominado THE (Technische Hogeschool, Eindhoven), de Dijkstra, que se utilizó con fines didácticos. Se puede pensar también en estos sistemas como si fueran `multicapa'. Multics y Unix caen en esa categoría.

En la estructura anterior se basan prácticamente la mayoría de los sistemas operativos actuales. Otra forma de ver este tipo de sistema es la denominada de anillos concéntricos o "rings".
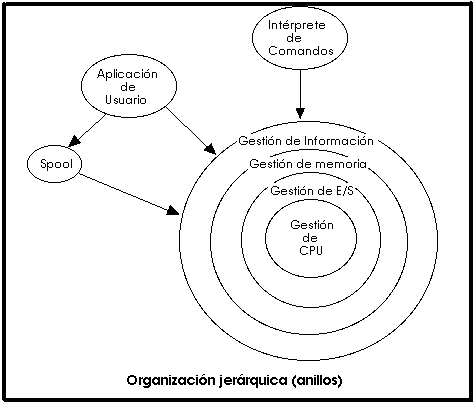
En el sistema de anillos, cada uno tiene una apertura, conocida como puerta o trampa (trap), por donde pueden entrar las llamadas de las capas inferiores. De esta forma, las zonas más internas del sistema operativo o núcleo del sistema estarán más protegidas de accesos indeseados desde las capas más externas. Las capas más internas serán, por tanto, más privilegiadas que las externas.
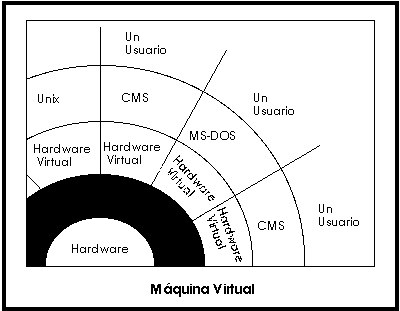
Máquina Virtual.
Se trata de un tipo de sistemas operativos que presentan una interface a cada proceso, mostrando una máquina que parece idéntica a la máquina real subyacente. Estos sistemas operativos separan dos conceptos que suelen estar unidos en el resto de sistemas: la multiprogramación y la máquina extendida. El objetivo de los sistemas operativos de máquina virtual es el de integrar distintos sistemas operativos dando la sensación de ser varias máquinas diferentes.
El núcleo de estos sistemas operativos se denomina monitor virtual y tiene como misión llevar a cabo la multiprogramación, presentando a los niveles superiores tantas máquinas virtuales como se soliciten. Estas máquinas virtuales no son máquinas extendidas, sino una réplica de la máquina real, de manera que en cada una de ellas se pueda ejecutar un sistema operativo diferente, que será el que ofrezca la máquina extendida al usuario
Cliente-Servidor(Microkernel).
El tipo más reciente de sistemas operativos es el denominado Cliente-servidor, que puede ser ejecutado en la mayoría de las computadoras, ya sean grandes o pequeñas.
Este sistema sirve para toda clase de aplicaciones por tanto, es de propósito general y cumple con las mismas actividades que los sistemas operativos convencionales.
El núcleo tiene como misión establecer la comunicación entre los clientes y los servidores. Los procesos pueden ser tanto servidores como clientes. Por ejemplo, un programa de aplicación normal es un cliente que llama al servidor correspondiente para acceder a un archivo o realizar una operación de entrada/salida sobre un dispositivo concreto. A su vez, un proceso cliente puede actuar como servidor para otro." [Alcal92]. Este paradigma ofrece gran flexibilidad en cuanto a los servicios posibles en el sistema final, ya que el núcleo provee solamente funciones muy básicas de memoria, entrada/salida, archivos y procesos, dejando a los servidores proveer la mayoría que el usuario final o programador puede usar. Estos servidores deben tener mecanismos de seguridad y protección que, a su vez, serán filtrados por el núcleo que controla el hardware. Actualmente se está trabajando en una versión de UNIX que contempla en su diseño este paradigma.
5. Sistemas Operativos por la Forma de Ofrecer sus Servicios
Esta clasificación también se refiere a una visión externa, que en este caso se refiere a la del usuario, el cómo accesa a los servicios. Bajo esta clasificación se pueden detectar dos tipos principales: sistemas operativos de red y sistemas operativos distribuidos.
Sistema Operativo de Red.
Los sistemas operativos de red se definen como aquellos que tiene la capacidad de interactuar con sistemas operativos en otras computadoras por medio de un medio de transmisión con el objeto de intercambiar información, transferir archivos, ejecutar comandos remotos y un sin fin de otras actividades. El punto crucial de estos sistemas es que el usuario debe saber la sintaxis de un conjunto de comandos o llamadas al sistema para ejecutar estas operaciones, además de la ubicación de los recursos que desee accesar. Por ejemplo, si un usuario en la computadora hidalgo necesita el archivo matriz.pas que se localiza en el directorio /software/codigo en la computadora morelos bajo el sistema operativo UNIX, dicho usuario podría copiarlo a través de la red con los comandos siguientes: hidalgo% hidalgo% rcp morelos:/software/codigo/matriz.pas . hidalgo%. En este caso, el comando rcp que significa "remote copy" trae el archivo indicado de la computadora morelos y lo coloca en el directorio donde se ejecutó el mencionado comando. Lo importante es hacer ver que el usuario puede accesar y compartir muchos recursos.
El primer Sistema Operativo de red estaba enfocado a equipos con un procesador Motorola 68000, pasando posteriormente a procesadores Intel como Novell Netware.
Los Sistemas Operativos de red mas ampliamente usados son: Novell Netware, Personal Netware, LAN Manager, Windows NT Server, UNIX, LANtastic.
Sistemas Operativos Distribuidos.
Los sistemas operativos distribuidos abarcan los servicios de los de red, logrando integrar recursos ( impresoras, unidades de respaldo, memoria, procesos, unidades centrales de proceso ) en una sola máquina virtual que el usuario accesa en forma transparente. Es decir, ahora el usuario ya no necesita saber la ubicación de los recursos, sino que los conoce por nombre y simplemente los usa como si todos ellos fuesen locales a su lugar de trabajo habitual. Todo lo anterior es el marco teórico de lo que se desearía tener como sistema operativo distribuido, pero en la realidad no se ha conseguido crear uno del todo, por la complejidad que suponen: distribuir los procesos en las varias unidades de procesamiento, reintegrar sub-resultados, resolver problemas de concurrencia y paralelismo, recuperarse de fallas de algunos recursos distribuidos y consolidar la protección y seguridad entre los diferentes componentes del sistema y los usuarios. Los avances tecnológicos en las redes de área local y la creación de microprocesadoresde 32 y 64 bits lograron que computadoras mas o menos baratas tuvieran el suficiente poder en forma autónoma para desafiar en cierto grado a los mainframes, y a la vez se dio la posibilidad de intercomunicarlas, sugiriendo la oportunidad de partir procesos muy pesados en cálculo en unidades más pequeñas y distribuirlas en los varios microprocesadores para luego reunir los sub-resultados, creando así una máquina virtual en la red que exceda en poder a un mainframe. El sistema integrador de los microprocesadores que hacer ver a las varias memorias, procesadores, y todos los demás recursos como una sola entidad en forma transparente se le llama sistema operativo distribuído. Las razones para crear o adoptar sistemas distribuidos se dan por dos razones principales: por necesidad ( debido a que los problemas a resolver son inherentemente distribuidos ) o porque se desea tener más confiabilidad y disponibilidad de recursos. En el primer caso tenemos, por ejemplo, el control de los cajeros automáticos en diferentes estados de la república. Ahí no es posible ni eficiente mantener un control centralizado, es más, no existe capacidad de cómputo y de entrada/salida para dar servicio a los millones de operaciones por minuto. En el segundo caso, supóngase que se tienen en una gran empresa varios grupos de trabajo, cada uno necesita almacenar grandes cantidades de información en disco duro con una alta confiabilidad y disponibilidad. La solución puede ser que para cada grupode trabajo se asigne una partición de disco duro en servidores diferentes, de manera que si uno de los servidores falla, no se deje dar el servicio a todos, sino sólo a unos cuantos y, más aún, se podría tener un sistema con discos en espejo ( mirror ) a través de la red, de manera que si un servidor se cae, el servidor en espejo continúa trabajando y el usuario ni cuenta se da de estas fallas, es decir, obtiene acceso a recursos en forma transparente.
Los sistemas distribuidos deben de ser muy confiables, ya que si un componente del sistema se compone otro componente debe de ser capaz de reemplazarlo.
Entre los diferentes Sistemas Operativos distribuidos que existen tenemos los siguientes: Sprite, Solaris-MC, Mach, Chorus, Spring, Amoeba, Taos, etc.
Uno de los conceptos mas importantes que gira entorno a un sistema operativo es el de proceso. Un proceso es un programa en ejecución junto con el entorno asociado (registros, variables ,etc.).
El corazón de un sistema operativo es el núcleo, un programa de control que reacciona ante cualquier interrupción de eventos externos y que da servicio a los procesos, creándolos, terminándolos y respondiendo a cualquier petición de servicio por parte de los mismos.
Planificación del Procesador.
La planificación del procesador se refiere a la manera o técnicas que se usan para decidir cuánto tiempo de ejecución y cuando se le asignan a cada proceso del sistema. Obviamente, si el sistema es monousuario y monotarea no hay mucho que decidir, pero en el resto de los sistemas esto es crucial para el buen funcionamiento del sistema.
Caracteristicas a considerar de los Procesos.
No todos los equipos de cómputo procesan el mismo tipo de trabajos, y un algoritmo de planificación que en un sistema funciona excelente puede dar un rendimiento pésimo en otro cuyos procesos tienen características diferentes. Estas características pueden ser:
- Cantidad de Entrada/Salida: Existen procesos que realizan una gran cantidad de operaciones de entrada y salida (aplicaciones de bases de datos, por ejemplo).
- Cantidad de Uso de CPU: Existen procesos que no realizan muchas operaciones de entrada y salida, sino que usan intensivamente la unidad central de procesamiento. Por ejemplo, operaciones con matrices.
- Procesos de Lote o Interactivos: Un proceso de lote es más eficiente en cuanto a la lectura de datos, ya que generalmente lo hace de archivos, mientras que un programa interactivo espera mucho tiempo (no es lo mismo el tiempo de lectura de un archivo que la velocidad en que una persona teclea datos) por las respuestas de los usuarios.
- Procesos en Tiempo Real: Si los procesos deben dar respuesta en tiempo real se requiere que tengan prioridad para los turnos de ejecución.
- Longevidad de los Procesos: Existen procesos que típicamente requerirán varias horas para finalizar su labor, mientras que existen otros que solo necesitan algunos segundos.
Un proceso es una actividad que se apoya en datos, recursos, un estado en cada momento y un programa.
El Bloque de Control de Procesos (PCB).
Un proceso se representa desde el punto de vista del sistema operativo, por un conjunto de datos donde se incluyen el estado en cada momento, recursos utilizados, registros, etc., denominado Bloque de Control de Procesos (PCB).
Los objetivos del bloque de control de procesos son los siguientes:
Localización de la información sobre el proceso por parte del sistema operativo.
Mantener registrados los datos del proceso en caso de tener que suspender temporalmente su ejecución o reanudarla.
La información contenida en el bloque de control es la siguiente:
Estado del proceso. Información relativa al contenido del controlador del programa (Program Counter, PC), estado de procesador en cuanto a prioridad del proceso, modo de ejecución, etc., y por ultimo el estado de los registros internos de la computadora.
Estadísticas de tiempo y ocupación de recursos para la gestión de la planificación del procesador.
Ocupación de memoria interna y externa para el intercambio (swapping).
Recursos en uso (normalmente unidades de entrada/salida).
Archivos en uso.
Privilegios.
Estas informaciones se encuentran en memoria principal en disco y se accede a ellas en los momentos en que se hace necesaria su actualización o consulta. Los datos relativos al estado del proceso siempre se encuentran en memoria principal.
Existe un Bloque de Control de Sistema (SCB) con objetivos similares al anterior y entre los que se encuentra el enlazado de los bloques de control de procesos existentes en el sistema.
El cambio de contexto se producirá en caso de ejecución de una instrucción privilegiada, una llamada al sistema operativo o una interrupción, es decir, siempre que se requiera la atención de algún servicio del sistema operativo.
Estado de los Procesos.
Los bloques de control de los procesos se almacenan en colas, cada una de las cuales representa un estado particular de los procesos, existiendo en cada bloque, entre otras informaciones. Los estados de los procesos son internos del sistema operativo y transparentes al usuario.
Los estados de los procesos se pueden dividir en dos tipos: activos e inactivos.
1.- Estados activos: Son aquellos que compiten con el procesador o están en condiciones de hacerlo. Se dividen en:
Ejecución. Estado en el que se encuentra un proceso cuando tiene el control del procesador. En un sistema monoprocesador este estado sólo lo puede tener un proceso.
Preparado. Aquellos procesos que están dispuestos para ser ejecutados, pero no están en ejecución por alguna causa (Interrupción, haber entrado en cola estando otro proceso en ejecución, etc.).
Bloqueado. Son los procesos que no pueden ejecutarse de momento por necesitar algún recurso no disponible (generalmente recursos de entrada/salida).
2.- Estados inactivos: Son aquellos que no pueden competir por el procesador, pero que pueden volver a hacerlo por medio de ciertas operaciones. En estos estados se mantiene el bloque de control de proceso aparcado hasta que vuelva a ser activado. Se trata de procesos que no han terminado su trabajo que lo han impedido y que pueden volver a activarse desde el punto en que se quedaron sin que tengan que volver a ejecutarse desde el principio.
Son de dos tipos:
- Suspendido bloqueado. Es el proceso que fue suspendido en espera de un evento, sin que hayan desaparecido las causas de su bloqueo.
- Suspendido programado. Es el proceso que han sido suspendido, pero no tiene causa parta estar bloqueado.
Operaciones sobre procesos.
Los sistemas operativos actuales poseen una serie de funciones cuyo objetivo es el de la manipulación de los procesos. Las operaciones que se pueden hacer sobre un proceso son las siguientes:
Crear el proceso. Se produce con la orden de ejecución del programa y suele necesitar varios argumentos, como el nombre y la prioridad del proceso. Aparece en este momento el PCB, que será insertado en la cola de procesos preparados.
La creación de un proceso puede ser de dos tipos:
Jerárquica. En ella, cada proceso que se crea es hijo del proceso creador y hereda el entorno de ejecución de su padre. El primer proceso que ejecuta un usuario será hijo del intérprete de comandos con el que interactúa.
No jerárquica. Cada proceso creado por otro proceso se ejecuta independientemente de su creador con un entorno diferente. Es un tipo de creación que no suele darse en los sistemas operativos actuales.
Destruir un proceso. Se trata de la orden de eliminación del proceso con la cual el sistema operativo destruye su PCB.
Suspender un proceso. Es un proceso de alta prioridad que paraliza un proceso que puede ser reanudado posteriormente. Suele utilizarse en ocasiones de mal funcionamiento o sobrecarga del sistema.
Reanudar un proceso. Trata de activar un proceso que a sido previamente suspendido.
Cambiar la prioridad de un proceso.
Temporizar la ejecución de un proceso. Hace que un determinado proceso se ejecute cada cierto tiempo (segundos, minutos, horas...) por etapas de una sola vez, pero transcurrido un periodo de tiempo fijo.
Despertar un proceso. Es una forma de desbloquear un proceso que habrá sido bloqueado previamente por temporización o cualquier otra causa.
Prioridades
Todo proceso por sus características e importancia lleva aparejadas unas determinadas necesidades de ejecución en cuanto a urgencia y asignación de recursos.
Las prioridades según los sistemas operativos se pueden clasificar del siguiente modo:
Asignadas por el sistema operativo. Se trata de prioridades que son asignadas a un proceso en el momento de comenzar su ejecución y dependen fundamentalmente de los privilegios de su propietario y del modo de ejecución.
- Asignadas por el propietario.
- Estáticas.
- Dinámicas.
El Núcleo del Sistema Operativo.
Todas las operaciones en las que participan procesos son controladas por la parte del sistema operativo denominada núcleo (nucleus, core o kernel, en inglés). El núcleo normalmente representa sólo una pequeña parte de lo que por lo general se piensa que es todo el sistema operativo, pero es tal vez el código que más se utiliza. Por esta razón, el núcleo reside por lo regular en la memoria principal, mientras que otras partes del sistema operativo son cargadas en la memoria principal sólo cuando se necesitan.
Los núcleos se diseñan para realizar "el mínimo" posible de procesamiento en cada interrupción y dejar que el resto lo realice el proceso apropiado del sistema, que puede operar mientras el núcleo se habilita para atender otras interrupciones.
El núcleo de un sistema operativo normalmente contiene el código necesario para realizar las siguientes funciones:
Manejo de interrupciones.
Creación y destrucción de procesos.
Cambio de estado de los procesos.
Despacho.
Suspensión y reanudación de procesos.
Sincronización de procesos.
Comunicación entre procesos.
Manipulación de los bloques de control de procesos.
Apoyo para las actividades de entrada/salida.
Apoyo para asignación y liberación de memoria.
Apoyo para el sistema de archivos.
Apoyo para el mecanismo de llamada y retorno de un procedimiento.
Apoyo para ciertas funciones de contabilidad del sistema.
Núcleo o Kernel y niveles de un Sistema Operativo.
El Kernel consiste en la parte principal del código del sistema operativo, el cual se encargan de controlar y administrar los servicios y peticiones de recursos y de hardware con respecto a uno o varios procesos, este se divide en 5 capas:
Nivel 1. Gestión de Memoria: que proporciona las facilidades de bajo nivel para la gestión de memoria secundaria necesaria para la ejecución de procesos.
Nivel 2. Procesador: Se encarga de activar los cuantums de tiempo para cada uno de los procesos, creando interrupciones de hardware cuando no son respetadas.
Nivel 3. Entrada/Salida: Proporciona las facilidades para poder utilizar los dispositivos de E/S requeridos por procesos.
Nivel 4. Información o Aplicación o Interprete de Lenguajes: Facilita la comunicación con los lenguajes y el sistema operativo para aceptar las ordenes en cada una de las aplicaciones. Cuando se solicitan ejecutando un programa el software de este nivel crea el ambiente de trabajo e invoca a los procesos correspondientes.
Nivel 5. Control de Archivos: Proporciona la facilidad para el almacenamiento a largo plazo y manipulación de archivos con nombre, va asignando espacio y acceso de datos en memoria.
El núcleo y los procesos.
El núcleo (Kernel) de un sistema operativo es un conjunto de rutinas cuya misión es la de gestionar el procesador, la memoria, la entrada/salida y el resto de procesos disponibles en la instalación. Toda esta gestión la realiza para atender al
funcionamiento y peticiones de los trabajos que se ejecutan en el sistema.
Los procesos relacionados con la entidad básica de los sistemas operativos actuales: Los procesos.
El esquema general del mismo es el siguiente:
Definición y concepto de proceso.
El Bloque de Control de Proceso (PCB) como imagen donde el sistema operativo ve el estado del proceso.
Estados por los que pasa un proceso a lo largo de su existencia en la computadora.
Operaciones que se pueden realizar sobre un proceso.
Clasificación de los procesos según su forma de ejecución, de carga, etc.
7. Dispositivos de Entrada y Salida.
El código destinado a manejar la entrada y salida de los diferentes periféricos en un sistema operativo es de una extensión considerable y sumamente complejo. Resuelve la necesidades de sincronizar, atrapar interrupciones y ofrecer llamadas al sistema para los programadores.
Los dispositivos de entrada salida se dividen, en general, en dos tipos: dispositivos orientados a bloques y dispositivos orientados a caracteres.
Orientados a Bloques.
Los dispositivos orientados a bloques tienen la propiedad de que se pueden direccionar, esto es, el programador puede escribir o leer cualquier bloque del dispositivo realizando primero una operación de posicionamiento sobre el dispositivo. Los dispositivos más comunes orientados a bloques son los discos duros, la memoria, discos compactos y, posiblemente, unidades de cinta.
Orientados a Caracteres.
Los dispositivos orientados a caracteres son aquellos que trabajan con secuencias de bytes sin importar su longitud ni ninguna agrupación en especial. No son dispositivos direccionables. Ejemplos de estos dispositivos son el teclado, la pantalla o display y las impresoras.
La clasificación anterior no es perfecta, porque existen varios dispositivos que generan entrada o salida que no pueden englobarse en esas categorías. Por ejemplo, un reloj que genera pulsos. Sin embargo, aunque existan algunos periféricos que no se puedan categorizar, todos están administrados por el sistema operativo por medio de una parte electrónica - mecánica y una parte de software.
8. Principios del Software de Entrada y Salida.
Los principios de software en la entrada - salida se resumen en cuatro puntos: el software debe ofrecer manejadores de interrupciones, manejadores de dispositivos, software que sea independiente de los dispositivos y software para usuarios.
Manejadores de Interrupciones.
El primer objetivo referente a los manejadores de interrupciones consiste en que el programador o el usuario no debe darse cuenta de los manejos de bajo nivel para los casos en que el dispositivo está ocupado y se debe suspender el proceso o sincronizar algunas tareas. Desde el punto de vista del proceso o usuario, el sistema simplemente se tardó más o menos en responder a su petición.
Manejadores de Dispositivos.
El sistema debe proveer los manejadores de dispositivos necesarios para los periféricos, así como ocultar las peculiaridades del manejo interno de cada uno de ellos, tales como el formato de la información, los medios mecánicos, los niveles de voltaje y otros. Por ejemplo, si el sistema tiene varios tipos diferentes de discos duros, para el usuario o programador las diferencias técnicas entre ellos no le deben importar, y los manejadores le deben ofrecer el mismo conjunto de rutinas para leer y escribir datos.
Software que sea independiente de los dispositivos.
Este es un nivel superior de independencia que el ofrecido por los manejadores de dispositivos. Aquí el sistema operativo debe ser capaz, en lo más posible, de ofrecer un conjunto de utilerías para accesar periféricos o programarlos de una manera consistente. Por ejemplo, que para todos los dispositivos orientados a bloques se tenga una llamada para decidir si se desea usar 'buffers' o no, o para posicionarse en ellos.
Software para Usuarios.
La mayoría de las rutinas de entrada - salida trabajan en modo privilegiado, o son llamadas al sistema que se ligan a los programas del usuario formando parte de sus aplicaciones y que no le dejan ninguna flexibilidad al usuario en cuanto a la apariencia de los datos. Existen otras librerías en donde el usuario si tiene poder de decisión (por ejemplo la llamada a "printf" en el lenguaje "C"). Otra facilidad ofrecida son las áreas de trabajos encolados (spooling areas), tales como las de impresión y correo electrónico.
9. Manejo de los Dispositivos de E/S.
En el manejo de los dispositivos de E/S es necesario, introducir dos nuevos términos:
Buffering (uso de memoria intermedia).
El buffering trata de mantener ocupados tanto la CPU como los dispositivos de E/S. La idea es sencilla, los datos se leen y se almacenan en un buffer, una vez que los datos se han leído y la CPU va a iniciar inmediatamente la operación con ellos, el dispositivo de entrada es instruido para iniciar inmediatamente la siguiente lectura. La CPU y el dispositivo de entrada permanecen ocupados. Cuando la CPU esté libre para el siguiente grupo de datos, el dispositivo de entrada habrá terminado de leerlos. La CPU podrá empezar el proceso de los últimos datos leídos, mientras el dispositivo de entrada iniciará la lectura de los datos siguientes.
Para la salida, el proceso es análogo. En este caso los datos de salida se descargan en otro buffer hasta que el dispositivo de salida pueda procesarlos.
Este sistema soluciona en forma parcial el problema de mantener ocupados todo el tiempo la CPU y los dispositivos de E/S. Ya que todo depende del tamaño del buffer y de la velocidad de procesamiento tanto de la CPU como de los dispositivos de E/S.
El manejo de buffer es complicado. Uno de los principales problemas reside en determinar tan pronto como sea posible que un dispositivo de E/S a finalizado una operación. Este problema se resuelve mediante las interrupciones. Tan pronto como un dispositivo de E/S acaba con una operación interrumpe a la CPU, en ese momento la CPU detiene lo que está haciendo e inmediatamente transfiere el control a una posición determinada. Normalmente las instrucciones que existen en esta posición corresponden a una rutina de servicio de interrupciones. La rutina de servicio de interrupción comprueba si el buffer no está lleno o no está vacío y entonces inicia la siguiente petición de E/S. La CPU puede continuar entonces el proceso interrumpido.
Cada diseño de computadora tiene su propio mecanismo de interrupción, pero hay varias funciones comunes que todos contemplan.
El buffering puede ser de gran ayuda pero pocas veces es suficiente.
Spooling.
El problema con los sistemas de cintas es que una lectora de tarjetas no podía escribir sobre un extremo mientras la CPU leía el otro. Los sistemas de disco eliminaron esa dificultad, moviendo la cabeza de un área del disco a otra.
En un sistema de discos, las tarjetas se leen directamente desde la lectora sobre el disco. La posición de las imágenes de las tarjetas se registran en una tabla mantenida por el sistema operativo. En la tabla se anota cada trabajo una vez leído. Cuando se ejecuta un trabajo sus peticiones de entrada desde la tarjeta se satisfacen leyendo el disco. Cuando el trabajo solicita la salida, ésta se copia en el buffer del sistema y se escribe en el disco. Cuando la tarea se ha completado se escribe en la salida realmente.
Esta forma de procesamiento se denomina spooling, utiliza el disco como un buffer muy grande para leer tan por delante como sea posible de los dispositivos de entrada y para almacenar los ficheros hasta que los dispositivos de salida sean capaces de aceptarlos.
La ventaja sobre el buffering es que el spooling solapa la E/S de un trabajo con la computación de otro. Es una característica utilizada en la mayoría de los sistemas operativos.
Afecta directamente a las prestaciones. Por el costo de algo de espacio en disco y algunas tablas, la CPU puede simultanear la computación de un trabajo con la E/S de otros. De esta manera, puede mantener tanto a la CPU como a los dispositivos de E/S trabajando con un rendimiento mucho mayor.
Además mantiene una estructura de datos llama job spooling, que hace que los trabajos ya leídos permanezcan en el disco y el sistema operativo puede seleccionar cual ejecutar, por lo tanto se hace posible la planificación de trabajos.
10. Administración de Archivos.
Un archivo es un conjunto de información, que se encuentra almacenada o guardada en la memoria principal del computador, en el disco duro, en el disquete flexible o en los discos compactos (Cd-Rom).
Antes de que un archivo pueda leerse o escribirse en él, debe abrirse, momento en el cual se verifican los permisos. Estos archivos se abren especificando en el computador la ruta de acceso al archivo desde el directorio raíz, que es la unidad principal del disco del computador, este puede ser un disco duro o disco flexible. Entonces el sistema operativo visualiza el entorno al abrir un archivo.
Uno de los problemas mas frecuentes en el manejo de archivos son los deadlock, un deadlock es una situación no deseada de espera indefinida y se da cuando en un grupo de procesos, dos o más procesos de ese grupo esperan por llevar a cabo una tarea que será ejecutada por otro proceso del mismo grupo, entonces se produce el bloqueo. Los bloqueos se dan tanto en los sistemas operativos tradicionales como en los distribuidos, solo que en estos últimos es más difícil de prevenirlos, evitarlos e incluso detectarlos, y si se los logra detectar es muy complicado solucionarlos ya que la información se encuentra dispersa por todo el sistema.
Una vez que un deadlock se detecta, es obvio que el sistema está en problemas y lo único que resta por hacer es una de dos cosas: tener algún mecanismo de suspensión o reanudación que permita copiar todo el contexto de un proceso incluyendo valores de memoria y aspecto de los periféricos que esté usando para reanudarlo otro día, o simplemente eliminar un proceso o arrebatarle el recurso, causando para ese proceso la pérdida de datos y tiempo.
Seguridad de un Sistema Operativo.
En los sistemas operativos se requiere tener una buena seguridad informática, tanto del hardware, programas y datos, previamente haciendo un balance de los requerimientos y mecanismos necesarios. Con el fin de asegurar la integridad de la información contenida.
Dependiendo de los mecanismos utilizados y de su grado de efectividad, se puede hablar de sistemas seguros e inseguros. En primer lugar, deben imponerse ciertas características en el entorno donde se encuentra la instalación de los equipos, con el fin de impedir el acceso a personas no autorizadas, mantener un buen estado y uso del material y equipos, así como eliminar los riesgos de causas de fuerza mayor, que puedan destruir la instalación y la información contenida.
En la actualidad son muchas las violaciones que se producen en los sistemas informáticos, en general por acceso de personas no autorizadas que obtienen información confidencial pudiendo incluso manipularla. En ocasiones este tipo de incidencias resulta grave por la naturalezade los datos; por ejemplo si se trata de datos bancarios, datos oficiales que puedan afectar a la seguridad de los estados, etc.
El software mal intencionado que se produce por diversas causas, es decir pequeños programas que poseen gran facilidad para reproducirse y ejecutarse, cuyos efectos son destructivos nos estamos refiriendo a los virus informáticos.
Para esto, se analizan cuestiones de seguridad desde dos perspectivas diferentes la seguridad externa y la seguridad interna.
Todos los mecanismos dirigidos a asegurar el sistema informático sin que el propio sistema intervenga en el mismo se engloban en lo que podemos denominar seguridad externa.
La seguridad externa puede dividirse en dos grandes grupos:
Seguridad física. Engloba aquellos mecanismos que impiden a los agentes físicos la destrucción de la información existente en el sistema; entre ellos podemos citar el fuego, el humo, inundaciones descargas eléctricas, campos magnéticos, acceso físico de personas con no muy buena intención, entre otros.
Seguridad de administración. Engloba los mecanismos más usuales para impedir el acceso lógico de personas físicas al sistema.
Todos los mecanismos dirigidos a asegurar el sistema informático, siendo el propio sistema el que controla dichos mecanismos, se engloban en lo que podemos denominar seguridad interna.
0 comentarios